

Web Scraping With BeautifulSoup 4 :
In Python, If we want to gather data from someone’s website then we basically use APIs. But there are lot of websites, where they don’t have APIs. In such case, we can use scraping technique to scrap data from someone’s website. We can perform web scraping with BeautifulSoup Python module.
Basically, BeautifulSoup is one of the useful module to scrape data from any website. Basically, It’s parse the html content of any web page and then scrap data within specific Html Tag.
Today, I’m going to give you full guide about How you can use BS4 module to scrap data from any website.
Installing Required Modules:
Here, we have to install two required modules to do web scraping. You can install these modules by using pip commands. These modules are:
- requests: install by using command: “pip install requests“
- beautifulsoup4: install by using command: “pip install beautifulsoup4“
requests module is used to get html web page of any website that we want to scrape. Then beautifulsoup4 module is used to scrape data from websites.
Now, Let’s begin our tutorial about web scraping with beautifulsoup 4:
Web Scraping With BS4:
Let me tell you that what data from which website we’re going to scrap today. Basically, we’re going to perform our web scraping on StackOverflow.
I want to scrap recent questions and their details asked on StackOverflow website. First of all we have to import some modules that we just installed. We will import BeautifulSoup class from bs4 module and after then we will import requests module.
from bs4 import BeautifulSoup
import requestsNow, we will create an object from our request module to get html of web page that we want to scrape. Let’s give this object a name “response”. Here, You have to enter website url under get method of request module like this:
response = requests.get("https://stackoverflow.com/questions/")Now we will create an object name “soup” from BeautifulSoup Class. In this BeautifulSoup, we have to fill two parameters. First parameter is used for fetching html content and second is used for parsing that html file.
For first parameter, we will use response object that contains our web page html. we will enter like response.text(for html content). In second parameter, we will enter “html.parse“, because we’re parsing html content like:
soup = BeautifulSoup(response.text, "html.parser")Inspecting Html:
Now, You have to visit that website that you want to scrap like SatackOverFlow/Questions. After then right click on element and you will see Inspect element option.
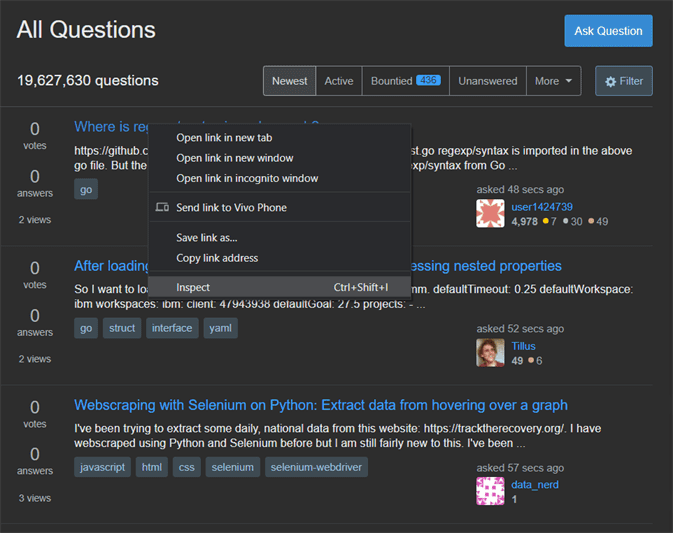
Now you will see all html tags of that web page. Here, you need to find all those html tags that contains your data that you want to scrap.
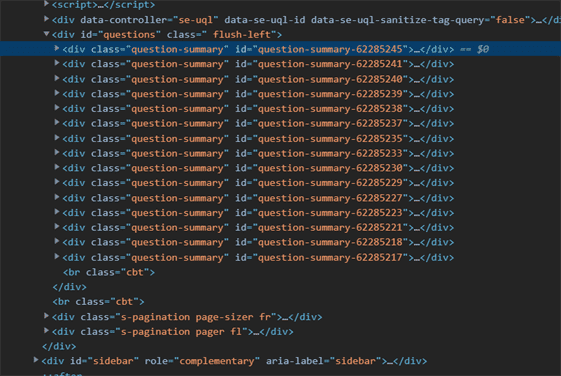
In this above image, You can see that our questions id contains all of the question of this web page. But we want only questions and their details, therefore, we will be looking inside tags that contains our question. Here, You can see that all of questions have same div tag with class name = question-summary.
Now, we will use select function in soup object to contains all html with these class name=”question-summary” like this:
questions = soup.select(".question-summary")In this above code, It will return a list that we’ve stored in questions variable. Now, we need to dig inside this div to find all those data. I’ve inspected and found that all questions are lies under the ahref link, which has a class name “question-hyperlink“.
We know that above questions is a kind of list, therefore we can access each element separately through an index no like:
print(questions[0].select(".question-hyperlink"))
But this above code will return a list. Therefore, you have to use select_one instead of select. But It will still return you question with anchor tags instead of plain text. Therefore, If you want to get plain text then you have to use getText() function in last like:
print(questions[0].select_one(".question-hyperlink").getText())
Result: Now you will simply get your question of index no. 0 from question list.
But Here, we want all of the questions from our web page. We have to use for loops to iterate over questions list. Basically I’m going to iterate all questions in question from list:
print(question.select_one(".question-hyperlink").getText())Run The Code and You will get such type of result in your terminal:

Congratulations, You’ve successfully scraped questions from StackOverFlow. I’ve final code for you, where I’ve also added vote-count and views:
You May Also Like: How To Send An Email In Python?(Read Here)
Python Web Scraping Code:
from bs4 import BeautifulSoup
import requests
response = requests.get("https://stackoverflow.com/questions/")
soup = BeautifulSoup(response.text, "html.parser")
questions = soup.select(".question-summary")
for question in questions:
title = question.select_one(".question-hyperlink").getText()
views = question.select_one(".views").getText()
vote_count = question.select_one(".vote-count-post").getText()
print(f"Title: {title}\nViews:{views}\nVote-Count: {vote_count}\n\n")Title: How to implement mac and dac at beginner to medium level?
Views:
3 views
Vote-Count: 0
Title: Using AppleScript to control Zoom
Views:
4 views
Vote-Count: 0
Title: What are difference between calling `connectGatt` on BluetoothDevice vs `connect` on BluetoothGatt
Views:
5 views
Vote-Count: 0
Title: GroupBy clause removing all null column values
Views:
7 views
Vote-Count: 0That’s it for today. It was the basic tutorial for beginners to getting start with BS4 for Web Scraping. We all know that python is one of the leading programming language for doing such kind of work e.g Web Scraping, Automation Etc.
If you found this article useful then please share this with your friends. You can also subscribe our blog via email to get notified with future posts.
&media=https://www.codechit.com/wp-content/uploads/2020/06/Photo_1591752682034_9009-1024x576.jpg){kind=link}
Thank’s For Reading…
2 thoughts on “Web Scraping With BeautifulSoup in Python(GUIDE)”